
![10 Years Of Cartographers Choice [at A Glance]](external/slider/slider_t_72145.jpg) 10 Years Of Cartographers Choice [at A Glance] - (65 comments)
10 Years Of Cartographers Choice [at A Glance] - (65 comments) Sahwyn - By Caenwyr - (12 comments)
Sahwyn - By Caenwyr - (12 comments) The Cartographers Guild Map - By MistyBeee - (28 comments)
The Cartographers Guild Map - By MistyBeee - (28 comments) Sundown - By Arsheesh - (24 comments)
Sundown - By Arsheesh - (24 comments) Valtoria - By ThomasR - (30 comments)
Valtoria - By ThomasR - (30 comments) Veduta Of A Late Medieval Town - By Chlodowech - (23 comments)
Veduta Of A Late Medieval Town - By Chlodowech - (23 comments)![10 Years Of Cartographers Choice [at A Glance]](external/slider/slider_72145.jpg)
For the 10th Anniversary, I decided to do a big mosaic of all the CCs on one page. It turned out a bit less mosaic than I planned but it's still nice to see them all together.

: Photoshop with graphic tablet & stylus Well-known member of the guild, Caenwyr is an accomplished cartographer who has explored many kinds of maps (regions, cities, worlds, buildings...

Hand drawn in Photoshop CC2020 using a Wacom Cintiq pro 16 Beside the name of the map - that alone should catch your attention - we can only admire here a superb depiction of a marvelous p...
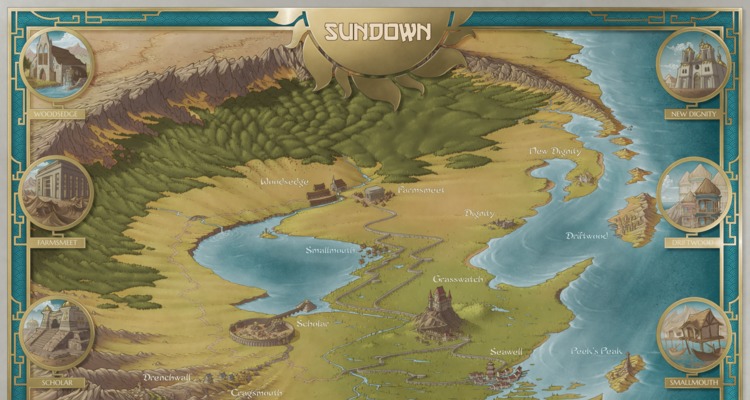
Arsheesh is a well-known member of the Guild who's been active for many years, and has constantly improved and polished his iconic maps during that time. What a surprise that he hasn't ha...
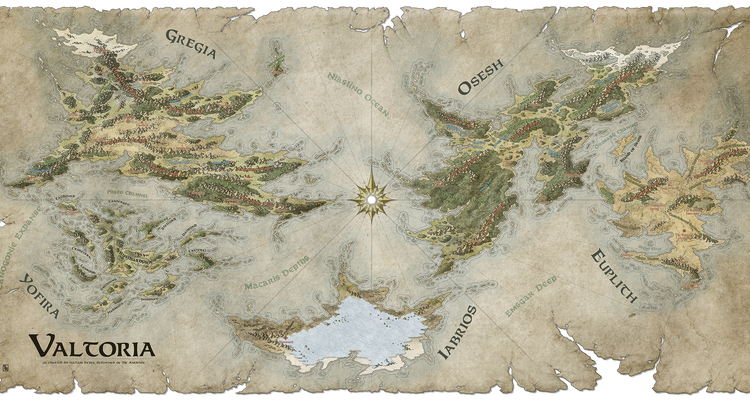
An active, supportive and prolific member of the Guild for years, ThomasR has outdone himself with this world map commission. The care and attention to land details, mountains, and shading...
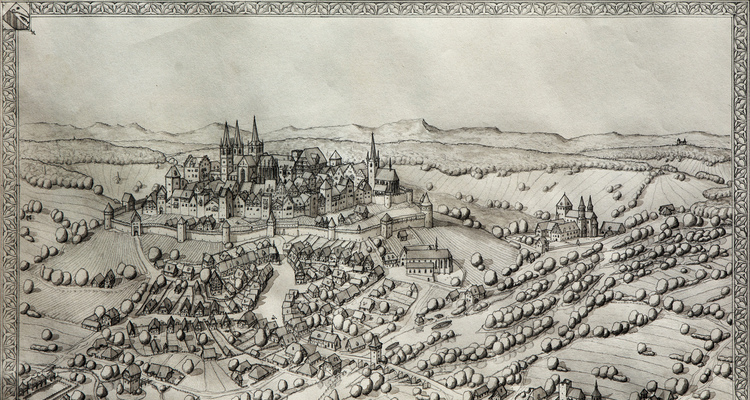
Chlodowech is an unmistakable artist for everyone who loves detailed, patiently crafted and designed historical maps. Working with traditional media, a map like Veduta is a beautiful tribute...
 Article Sections
Article Sections Article Categories
Article Categories Recent Forum Threads
Recent Forum Threads




Jörðgard Maps No. 514 - Fork in the Trail
Thread Starter: Mark Oliva
Last Post By: Mark Oliva Today, 05:03 AMJorðgarð Map 514 is a generic battlemap base for a fork in a deciduous forest in autumn. It comes from the pending Jörðgarð adventure